MySQL_tutorial
安装
下载
下载地址, 版本选择 ARM 64-bit DMG
配置密码
选择 :USE Legacy Password Encryption
root passwd 81604152
环境变量配置
1 | sudo vim ~/.zshrc |
登陆
1 | mysql -u root -p |
基础
基础操作
刚刚使用mysql时, 进行简单的实验代码
-
登陆mysql数据库
1
mysql -u root -p
-
创建一个简单的数据库
1
create database db01; # 如果需要删除的话 drop databasename;
-
选择当前自己创建的的数据库
1
use databasename;
-
查询数据表
1
show tables; #初始的状态下就是 empty set
-
创建数据库表
创建表一个简单的表
1
2
3
4
5
6
7CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50),
age INT,
gender ENUM('male', 'female')
);
#如果需要删除表的话 drop table users; -
查看表的结构信息
1
desc users;
-
数据库表中的基本crud(create read update delete)操作 基本
curd操作参考本篇文章
-
查询表
1
select * from users; # select item from users item: age name id
-
插入一条数据
1
insert into users (id, name, age, gender) values(1, 'alan', 20, 'male');
-
删除数据
1
delete from users where id = 1
-
更新一条数据
1
update users set name = 'alan-steve' where id = 3
-
DDL (数据定义语言)
Data Definiation Language
数据库操作
查询
查询所有数据库SHOW DATABASES;
1 | show databases; |
查询当前的数据库:SELECT DATABASE();
1 | select database(); |
创建
[ ] 中的内容为可以可以选参数
CREATE DATABASE [ IF NOT EXISTS ] 数据库名 [ DEFAULT CHARSET 字符集] [COLLATE 排序规则 ];
1 | create database dbname; |
删除
DROP DATABASE [ IF EXISTS ] 数据库名;
1 | drop DATABASE databasename; |
使用
USE 数据库名;
1 | use databasename; |
数据表操作
查询所有表
SHOW TABLES;
1 | show tables; |
查询表结构
DESC 表名;
1 | desc tablename; |
查询指定表的创建语句
SHOW CREATE TABLE 表名;
1 | show create table tablename; |
创建表
注意: 最后一个字段后面没有逗号
1 | CREATE TABLE 表名( |
删除表
DROP TABLE [IF EXISTS] 表名;
表字段操作
添加表字段
ALTER TABLE 表名 ADD 字段名 类型(长度) [COMMENT 注释] [约束];
1 | alter table users add nicknake varchar(50) comment 'nickname' |
删除字段
ALTER TABLE 表名 DROP 字段名;
1 | alter table users drop nickname; |
修改字段名字段类型
ALTER TABLE 表名 CHANGE 旧字段名 新字段名 类型(长度) [COMMENT 注释] [约束];
1 | alter table users change nickname username varchar(30); |
修改表名字
ALTER TABLE 表名 RENAME TO 新表名
DML(数据操作语言)
添加数据
-
指定字段
INSERT INTO 表名 (字段名1, 字段名2, ...) VALUES (值1, 值2, ...);1
insert into users(id, name, age, gender) values(5, 'jobs', 20, 'male');
-
全部字段
INSERT INTO 表名 VALUES (值1, 值2, ...);1
insert into users(10, 'job', 22, 'male');
-
批量添加数据- 自定字段
INSERT INTO 表名 (字段名1, 字段名2, ...) VALUES (值1, 值2, ...), (值1, 值2, ...), (值1, 值2, ...);1
-
批量添加数据- 全部字段
INSERT INTO 表名 VALUES (值1, 值2, ...), (值1, 值2, ...), (值1, 值2, ...);1
更改数据
修改数据:
UPDATE 表名 SET 字段名1 = 值1, 字段名2 = 值2, ... [ WHERE 条件 ];
1 | update users set name = 'davis', age = 30 where id = 3; |
删除数据
DELETE FROM 表名 [ WHERE 条件 ];
1 | delete from users where id = 3; |
DQL(数据库查询语言)
数据库的查询操作
1 | create table emp( |
1 | insert into emp(id, workno, name, gender, age, idcard, workaddress, entrydate) |
语法
1 | SELECT |
基础查询
查询多个字段
SELECT 字段1, 字段2, 字段3, ... FROM 表名;
SELECT * FROM 表名;
1 | select name, workno, age from emp; |
设置别名
SELECT 字段1 [ AS 别名1 ], 字段2 [ AS 别名2 ], 字段3 [ AS 别名3 ], ... FROM 表名;
SELECT 字段1 [ 别名1 ], 字段2 [ 别名2 ], 字段3 [ 别名3 ], ... FROM 表名;
1 | select workaddress as '工作地址' from emp; |
删除重复字段
SELECT DISTINCT 字段列表 FROM 表名;
1 | select distinct workaddress '工作地址' from emp; |
条件查询
条件
| 比较运算符 | 功能 |
|---|---|
| > | 大于 |
| >= | 大于等于 |
| < | 小于 |
| <= | 小于等于 |
| = | 等于 |
| <> 或 != | 不等于 |
| BETWEEN … AND … | 在某个范围内(含最小、最大值) |
| IN(…) | 在in之后的列表中的值,多选一 |
| LIKE 占位符 | 模糊匹配(_匹配单个字符,%匹配任意个字符) |
| IS NULL | 是NULL |
逻辑连接符号
| 逻辑运算符 | 功能 |
|---|---|
| AND 或 && | 并且(多个条件同时成立) |
| OR 或 || | 或者(多个条件任意一个成立) |
| NOT 或 ! | 非,不是 |
常见案例
1 | -- 年龄等于30 |
聚合查询
常见聚合函数
| 函数 | 功能 |
|---|---|
| count | 统计数量 |
| max | 最大值 |
| min | 最小值 |
| avg | 平均值 |
| sum | 求和 |
注意: 如果是某个字段的值为null, 则不统计
1 | select count(*) from emp; |
分组查询
语法:
SELECT 字段列表 FROM 表名 [ WHERE 条件 ] GROUP BY 分组字段名 [ HAVING 分组后的过滤条件 ];
where 和 having 的区别:
- 执行时机不同:where是分组之前进行过滤,不满足where条件不参与分组;having是分组后对结果进行过滤。
- 判断条件不同:where不能对聚合函数进行判断,而having可以。
1 | -- 根据性别分组,统计男性和女性数量(只显示分组数量,不显示哪个是男哪个是女) |
注意事项
- 执行顺序:where > 聚合函数 > having
- 分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无任何意义, (查询字段和分组字段 一致, 并且保持)
排序查询
查询的语法
语法 :
SELECT 字段列表 FROM 表名 ORDER BY 字段1 排序方式1, 字段2 排序方式2;
排序方式:
- ASC: 升序(默认)
- DESC: 降序
1 | -- 根据年龄升序排序 |
分页查询
语法:
SELECT 字段列表 FROM 表名 LIMIT 起始索引, 查询记录数;
案例:
1 | -- 查询第一页数据,展示10条 |
注意:
- 如果查询的是第一页数据,起始索引可以省略,直接简写 LIMIT 10
练习
-
查询年龄为20, 21, 23 的女员工信息。
1
2select * from emp where gender = '女' && age = 20 or age = 21 or age = 23;
select * from emp where gender = '女' && age in(20, 21, 23); -
查询性别为男, 并且年龄在20-40岁的以内的名字为三个字的员工 (这里三个字 使用like 关键字还是没有掌握)
1
select * from emp where gender = '男' && age >= 20 && age <= 40 && name like '___';
-
统计员工表, 年龄小于60岁男性员工和 女性员工的数量
1
select gender, count(*) from emp where age < 60 group by gender;
-
查询所有年龄小于等于35岁员工的姓名和年龄 年龄升序, 如果相同的话 入职时间升序
1
select name, age from emp where age <= 35 order by age asc, entrydate asc;
-
查询性别为男, 并且年龄在20-40 前5名员工, 年龄升序, 如果相同的话 入职时间升序(不会写前5名员工
1
select * from emp where age between 20 and 40 order by age asc, entrydate asc limit 0, 5;
DQL执行顺讯
FROM -> WHERE -> GROUP BY -> SELECT -> ORDER BY -> LIMIT
1 | select |
DCL (没重点看)
函数(没重点看)
字符串函数
| 函数 | 功能 |
|---|---|
| CONCAT(s1, s2, …, sn) | 字符串拼接,将s1, s2, …, sn拼接成一个字符串 |
| LOWER(str) | 将字符串全部转为小写 |
| UPPER(str) | 将字符串全部转为大写 |
| LPAD(str, n, pad) | 左填充,用字符串pad对str的左边进行填充,达到n个字符串长度 |
| RPAD(str, n, pad) | 右填充,用字符串pad对str的右边进行填充,达到n个字符串长度 |
| TRIM(str) | 去掉字符串头部和尾部的空格 |
| SUBSTRING(str, start, len) | 返回从字符串str从start位置起的len个长度的字符串 |
| REPLACE(column, source, replace) | 替换字符串 |
1 | -- 拼接 |
案例 将员工工号统一为5位数,并在前补0
1 | update emp set workno = lpad(work, 5, '0'); |
数值函数
常见的数值函数
| 函数 | 功能 |
|---|---|
| CEIL(x) | 向上取整 |
| FLOOR(x) | 向下取整 |
| MOD(x, y) | 返回x/y的模 |
| RAND() | 返回0~1内的随机数 |
| ROUND(x, y) | 求参数x的四舍五入值,保留y位小数 |
随机生成六位的验证码
1 | select lpad(round( rand() * 1000000, 0), 6, '0'); |
日期函数
常见函数:
| 函数 | 功能 |
|---|---|
| CURDATE() | 返回当前日期 |
| CURTIME() | 返回当前时间 |
| NOW() | 返回当前日期和时间 |
| YEAR(date) | 获取指定date的年份 |
| MONTH(date) | 获取指定date的月份 |
| DAY(date) | 获取指定date的日期 |
| DATE_ADD(date, INTERVAL expr type) | 返回一个日期/时间值加上一个时间间隔expr后的时间值 |
| DATEDIFF(date1, date2) | 返回起始时间date1和结束时间date2之间的天数 |
流程函数
约束
分类:
| 约束 | 描述 | 关键字 |
|---|---|---|
| 非空约束 | 限制该字段的数据不能为null | NOT NULL |
| 唯一约束 | 保证该字段的所有数据都是唯一、不重复的 | UNIQUE |
| 主键约束 | 主键是一行数据的唯一标识,要求非空且唯一 | PRIMARY KEY |
| 默认约束 | 保存数据时,如果未指定该字段的值,则采用默认值 | DEFAULT |
| 检查约束(8.0.1版本后) | 保证字段值满足某一个条件 | CHECK |
| 外键约束 | 用来让两张图的数据之间建立连接,保证数据的一致性和完整性 | FOREIGN KEY |
约束是作用于表中字段上的,可以再创建表/修改表的时候添加约束。
常用约束
| 约束条件 | 关键字 |
|---|---|
| 主键 | PRIMARY KEY |
| 自动增长 | AUTO_INCREMENT |
| 不为空 | NOT NULL |
| 唯一 | UNIQUE |
| 逻辑条件 | CHECK |
| 默认值 | DEFAULT |
1 | create table user |
外键约束
创建外键,
1 | CREATE TABLE 表名( |
创建外键
1 | alter table emp add constraint fk_emp_dept_id foreign key(dept_id) references dept(id); |
删除外键
ALTER TABLE 表名 DROP FOREIGN KEY 外键名;
外键删除更新行为
删除/更新行为
| 行为 | 说明 |
|---|---|
| NO ACTION | 当在父表中删除/更新对应记录时,首先检查该记录是否有对应外键,如果有则不允许删除/更新(与RESTRICT一致) |
| RESTRICT | 当在父表中删除/更新对应记录时,首先检查该记录是否有对应外键,如果有则不允许删除/更新(与NO ACTION一致) |
| CASCADE | 当在父表中删除/更新对应记录时,首先检查该记录是否有对应外键,如果有则也删除/更新外键在子表中的记录 |
| SET NULL | 当在父表中删除/更新对应记录时,首先检查该记录是否有对应外键,如果有则设置子表中该外键值为null(要求该外键允许为null) |
| SET DEFAULT | 父表有变更时,子表将外键设为一个默认值(Innodb不支持) |
1 | alter table emp add constraint fk_emp_dept_id foreign key(dept_id) references dept(id) on update cascade on delete cascade ; |
多表查询(重点)
多表关系
多表关系 :主要包含三种
- 一对多(多对一)
- 多对多
- 一对一
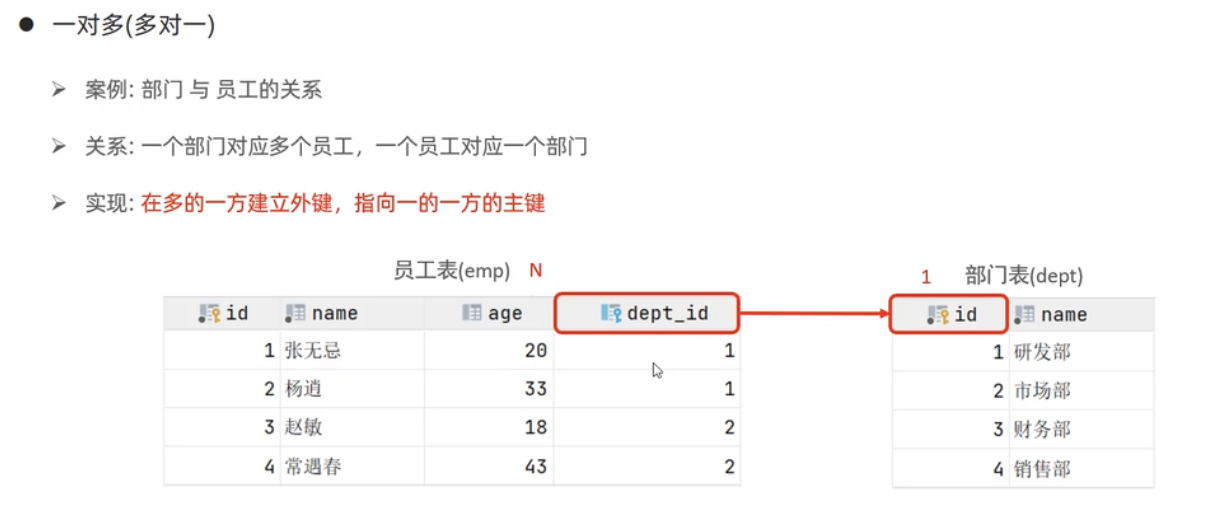
一对多
案例:部门与员工
关系:一个部门对应多个员工,一个员工对应一个部门
实现:在多的一方建立外键,指向一的一方的主键
一对多关系
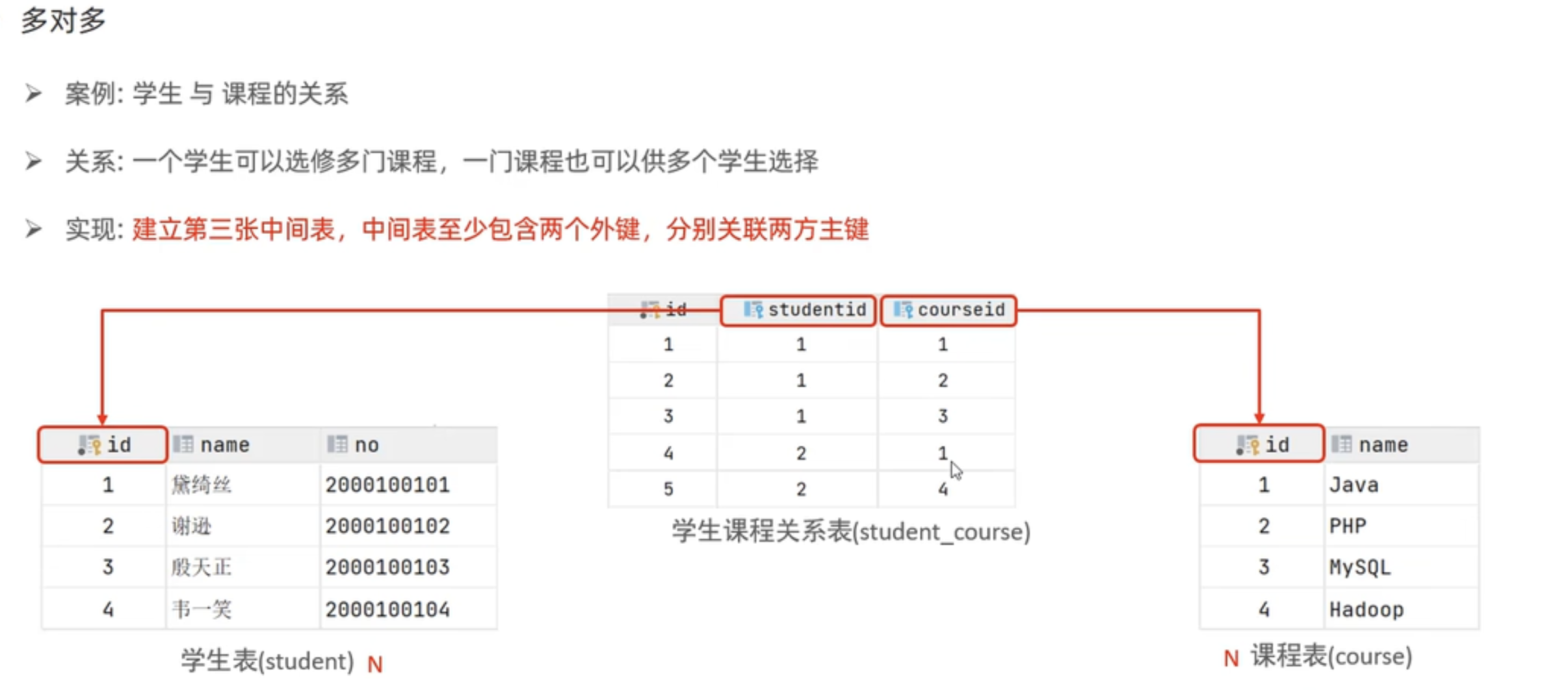
多对多
多对多关系:
案例:学生与课程
关系:一个学生可以选多门课程,一门课程也可以供多个学生选修
实现:建立第三张中间表,中间表至少包含两个外键,分别关联两方主键
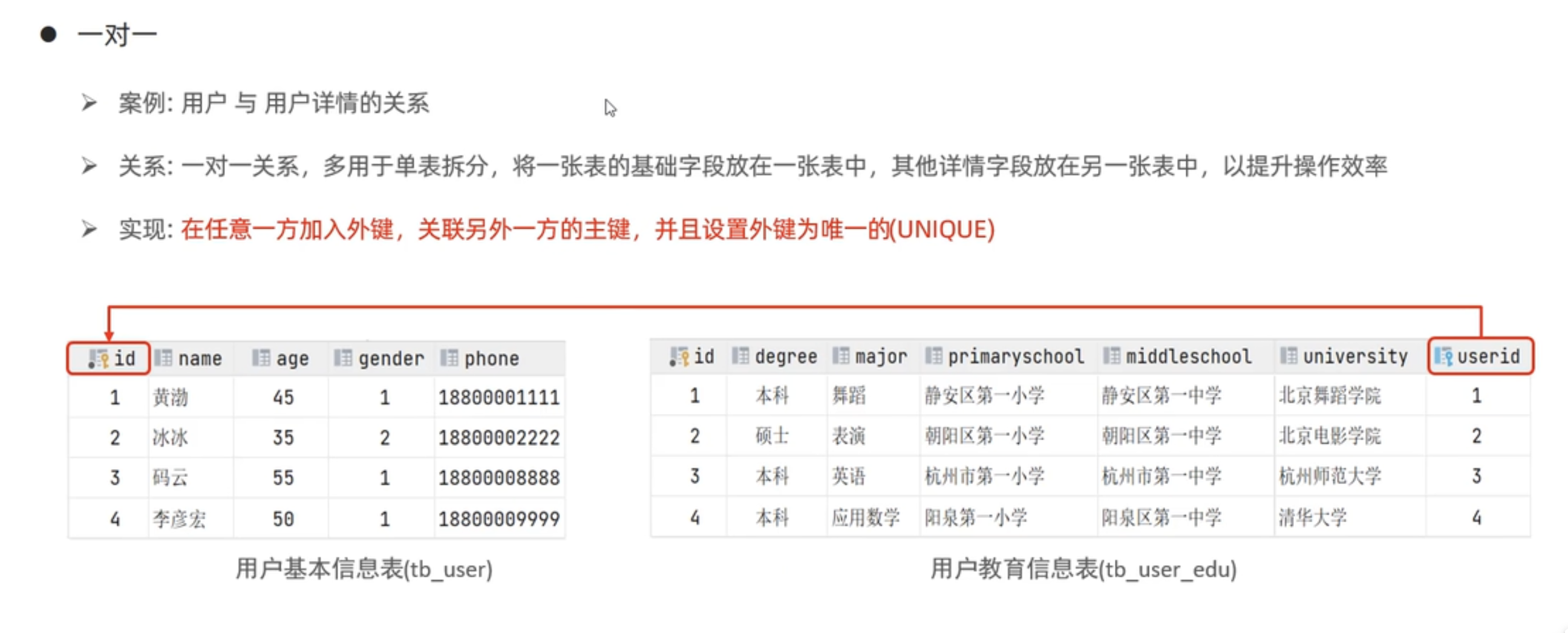
一对一
多表查询
1 | -- 准备数据 |
薪资水平表
1 | create table salgrade( |
基础的查询
1 | # 笛卡尔积查询 |
多表查询分类
连接查询
内连接
内连接就是查询两张表交集的部分。
隐式内连接
SELECT 字段列表 FROM 表1, 表2 WHERE 条件 ...;
1 | # 查询每个员工的姓名 ,以及关联的部门的名称 |
显式内连接
SELECT 字段列表 FROM 表1 [ INNER ] JOIN 表2 ON 连接条件 ...;
1 | # 查询每个员工的姓名 ,以及关联的部门的名称 |
外连接
左外连接
左外连接:
查询左表所有数据,以及两张表交集部分数据
SELECT 字段列表 FROM 表1 LEFT [ OUTER ] JOIN 表2 ON 条件 ...;
相当于查询表1的所有数据,包含表1和表2交集部分数据
重点是 左侧, 左侧是全部查询的部分 在join 关键字的左侧
1 | select e.*, d.name from emp e left outer join dept d on e.dept_id = d.id; |
右外连接
查询右表所有数据,以及两张表交集部分数据
SELECT 字段列表 FROM 表1 RIGHT [ OUTER ] JOIN 表2 ON 条件 ...;
重点是 右侧, 右侧为全部查询的部分, 在join关键字的右侧
1 | # 查询dept所有数据 以及对应的员工名称 |
总结: 其实并不用过度 纠结与使用使用那个语句(left/ right join ), 主需要关注那个是重点查询的即可,
- 使用right 重点放在 join右侧
- 使用left 重点放在left左侧
所以选择一个连接方式就可以解决需求。
自链接
SELECT 字段列表 FROM 表A 别名A JOIN 表A 别名B ON 条件 ...;
自连接可以选择内连接和外连接。
对于自链接的理解是:查询一个表中两个有关联的字段 比如
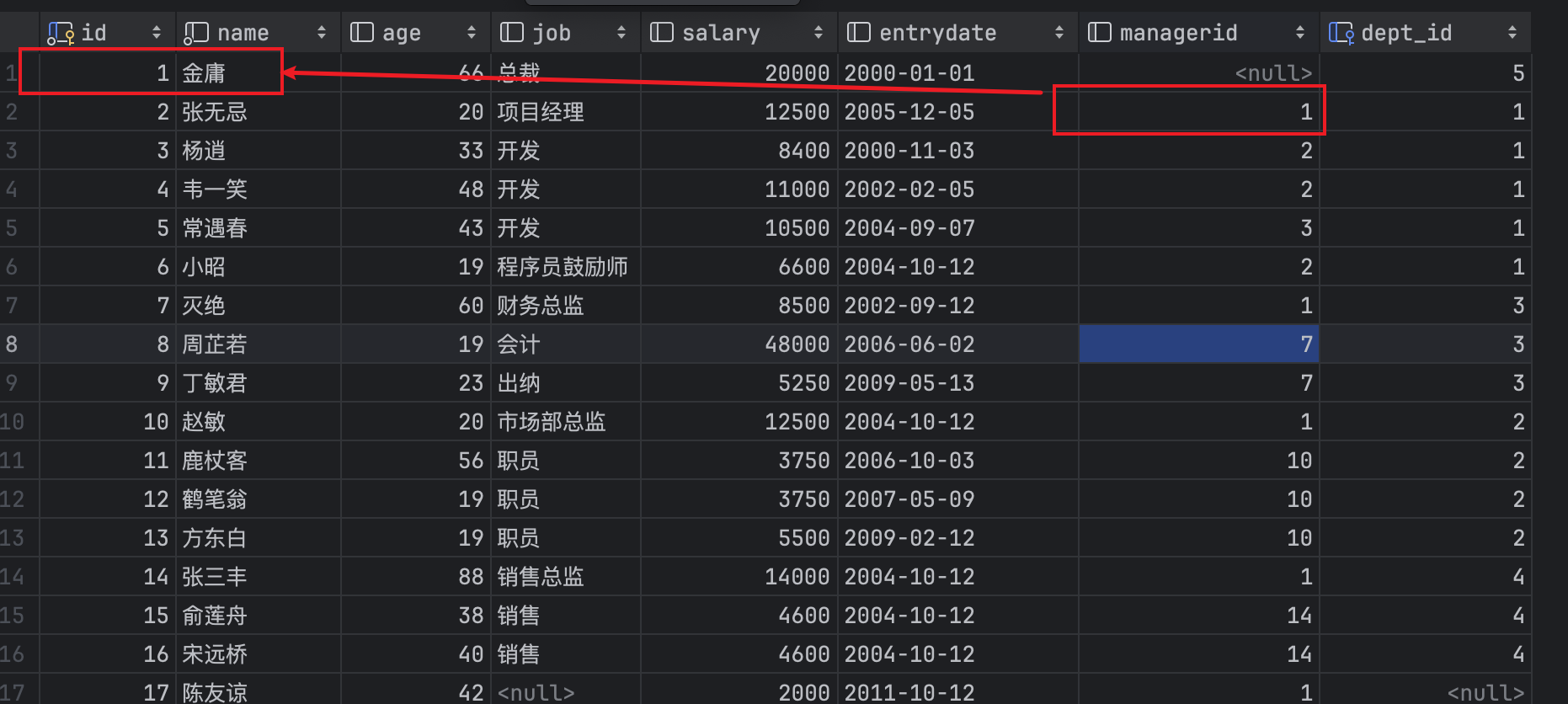
员工和老板之间的关系,张无忌的老板就是金庸, 现在需要查询所有员工 以及对应老板的信息, 此时就看作两张表进行连接 emp.managerid = emp.id
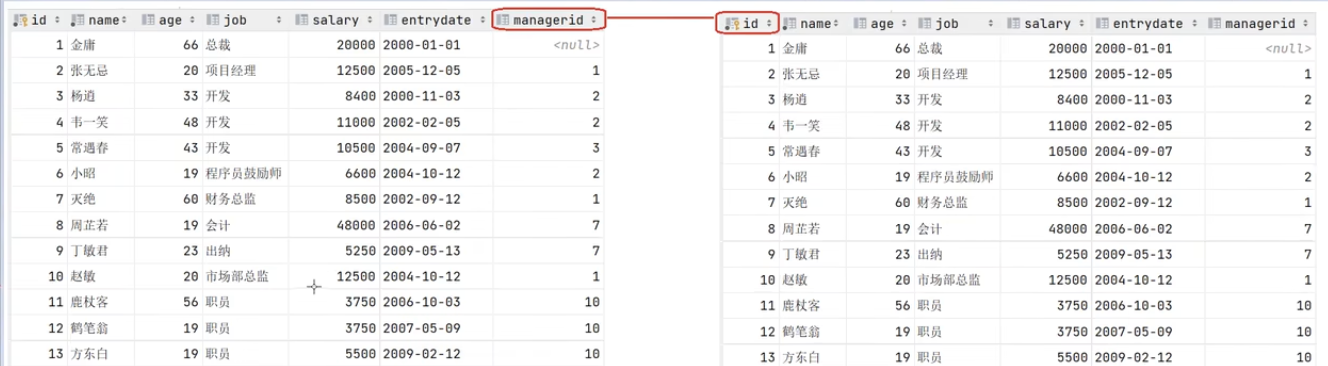
隐式内连接
1 | select e1.name, e2.name from emp e1, emp e2 where e1.managerid = e2.id; |
左外连接
1 | select e1.name as '员工', e2.name '领导' from emp e1 left join emp e2 on e1.managerid = e2.id; |
联合查询
把多次查询的结果合并,形成一个新的查询集
1 | SELECT 字段列表 FROM 表A ... |
ALL 关键字不会将结果去掉重复, 去掉ALL就会将结果去重
注意事项
- UNION ALL 会有重复结果,UNION 不会
- 联合查询比使用or效率高,不会使索引失效
- 联合查询多张表的列数和字段以及类型需要保持一致
子查询
SQL语句中嵌套SELECT语句,称谓嵌套查询,又称子查询。
SELECT * FROM t1 WHERE column1 = ( SELECT column1 FROM t2);
子查询外部的语句可以是 INSERT / UPDATE / DELETE / SELECT 的任何一个
根据子查询结果可以分为:
- 标量子查询(子查询结果为单个值)
- 列子查询(子查询结果为一列)
- 行子查询(子查询结果为一行)
- 表子查询(子查询结果为多行多列)
标量子查询
子查询返回的结果是单个值(数字、字符串、日期等)。
常用操作符:- < > > >= < <=
查询语句: 查询 销售部 所有员工信息
转化为两个子操作
-
查询销售部id
1
select id from dept where name = '销售部';
-
根据部门id查询员工信息
1
select * from emp where dept_id = 4;
整合以上的两个操作
1 | select * from emp where dept_id = (select id from dept where name = '销售部'); |
查询方东白之后入职信息
1 | select entrydate from emp where name = '方东白'; |
列子查询
子查询返回的结果是一列(可以是多行)。
常用操作符:
| 操作符 | 描述 |
|---|---|
| IN | 在指定的集合范围内,多选一 |
| NOT IN | 不在指定的集合范围内 |
| ANY | 子查询返回列表中,有任意一个满足即可 |
| SOME | 与ANY等同,使用SOME的地方都可以使用ANY |
| ALL | 子查询返回列表的所有值都必须满足 |
查询要求:查询市场部和销售部所有员工信息
-
查询两个部门id
1
select id from dept where name = '销售部' or name = '市场部';
-
根据两个部门id 查询所有员工信息
1
select * from emp where dept_id in(select id from dept where name = '销售部' or name = '市场部');
查询要求:查询比 财务部 所有人工资高的员工信息
-
查询所有财务部 人员工资
1
select salary from emp where dept_id = (select id from dept where name = '财务部');
-
查询比所有人薪资高
使用关键字 all
1
select * from emp where salary > all(select salary from emp where dept_id = (select id from dept where name = '财务部'));
查询要求:查询比 研发部 任意一人工资高的员工信息
-
查询所有研发部门人员工资
1
2select id from dept where name = '研发部';
select salary from emp where dept_id = (select id from dept where name = '研发部'); -
查询比 研发部 任意一人工资高的员工信息
1
select * from emp where salary > any (select salary from emp where dept_id = (select id from dept where name = '研发部'));
行子查询
子查询返回的结果是一行(可以是多列)
常用操作符:=, <, >, IN, NOT IN
查询要求:查询与 张无忌薪资以及直属领导相同的员工信息。
-
查询张无忌薪资以及领导
1
select salary, managerid from emp where name = '张无忌';
-
查询与 张无忌薪资以及直属领导相同的员工信息。
1
select * from emp where (salary, managerid) = (select salary, managerid from emp where name = '张无忌');
表子查询
返回的结果是多行多列
常用操作符:IN
查询需求: 查询与 鹿杖客和宋远桥的 职位和薪资相同的员工信息
-
查询两人的职位和薪资
1
select job, salary from emp where name = '鹿杖客' or name = '宋远桥';
-
查询与二者相同的数据
1
select * from emp where (job, salary) in (select job, salary from emp where name = '鹿杖客' or name = '宋远桥');
查询需求:查询入职日期是 2006-01-01 之后的员工信息,以及部门信息。
-
查询入职日期是2006-01-01 之后的员工信息
1
select * from emp where entrydate > '2006-01-01';
-
将第一步查询的活得的表作为一个表, 在这个表的基础上再查询员工信息以及部门的信息。
1
2
3select * from (select * from emp where entrydate > '2006-01-01') e left join dept d on e.dept_id = d.id;
# 修改想要查询的具体内容
select e.*, d.* from (select * from emp where entrydate > '2006-01-01') e left join dept d on e.dept_id = d.id;
练习题目
-
查询员工的姓名,年龄,职位, 部门信息
显式内连接(没有起别名)
1
select emp.name, emp.age, emp.job, dept.name from emp join dept where emp.dept_id = dept.id;
左外连接
1
select e.name, e.age, e.job, d.name from emp e left join dept d on e.dept_id = d.id;
-
查询年龄小于30的员工的姓名,年龄, 职位和部门信息
1
select e.age, e.job, d.name from emp e left join dept d on e.dept_id = d.id where e.age < 30;
-
查询拥有员工的部门id、部门名称
1
select e.name, d.id, d.name from emp e left join dept d on e.dept_id = d.id;
-
查询所有年龄大于40的员工,以及归属部门名称; 如果员工没有分配部门, 也需要展示出来
1
select e.name, d.name from emp e left join dept d on e.dept_id = d.id where e.age > 40 order by e.age desc;
-
查询所有员工的工资等级
关键一点: 确定连接条件 emp.salary>= salgrade.losal and emp.salary <= salgrade.hisal;
1
select e.name, e.salary, s.grade from emp e left join salgrade s on e.salary >= s.losal && e.salary <= s.hisal;
-
查询研发部所有员工的信息以及工资等级
使用子查询的方式:
1
select e.*, s.grade from emp e left join salgrade s on e.salary >= s.losal && e.salary <= s.hisal where e.dept_id = (select id from dept where name = '研发部');
-
查询研发部员工的平均工资
使用子查询的方式:
1
select avg(salary) from emp where dept_id = (select id from dept where name = '研发部');
-
查询工资比灭绝高的的员工信息
1
select * from emp where salary > (select salary from emp where name = '灭绝');
-
查询比平均薪资高的员工信息
1
select * from emp where salary > (select avg(salary) from emp);
-
查询低于本部门平均工资的员工信息
本题思路和讲解思路不一致:
稍微有一点点思维难度, 说说思考过程
-
查询每个部门的平均工资上来想到了 group by 和内连接 , 通过 group by 计算avg(salary), 本次查询的结果为表字段为dept_id, avg_sal
1
select d.id as id, avg(e.salary) as avgsal from emp e join dept d on e.dept_id = d.id group by e.dept_id;
-
通过第一步获取的表和emp进行表的子链接即可
1
select * from emp e join (select d.id as id, avg(e.salary) as avgsal from emp e join dept d on e.dept_id = d.id group by e.dept_id) item on e.dept_id = item.id where e.salary < item.avgsal;
-
-
查询所有部门信息,并统计员工的人数
本题思路与讲解思路不一致:
1
select d.name, count(*) from emp e join dept d on e.dept_id = d.id group by e.dept_id;
-
查询所有的学生的选课情况,并且展示 学生的名称, 学号,课程名称
事务
概念
事务:事务是一组操作的集合,事务会把所有操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。
事务操作
创建表
1 | -- 数据准备 |
事务的四大特性
- 原子性(Atomicity):事务是不可分割的最小操作但愿,要么全部成功,要么全部失败
- 一致性(Consistency):事务完成时,必须使所有数据都保持一致状态
- 隔离性(Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行
- 持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的

